DataScript as a Lingua Franca for domain modeling
- The approach
- The Domain Model
- The 'Machine Aspects'
- The problem
- From domain representation to machine execution
- Enter DataScript
- Tradeoffs and limitations
- Prior art
- Plumbing-first vs Domain-first
- Adaptable vs Principled
- You're in the business of framework-authoring
- Experience report: BandSquare
- Annex: a DataScript refresher
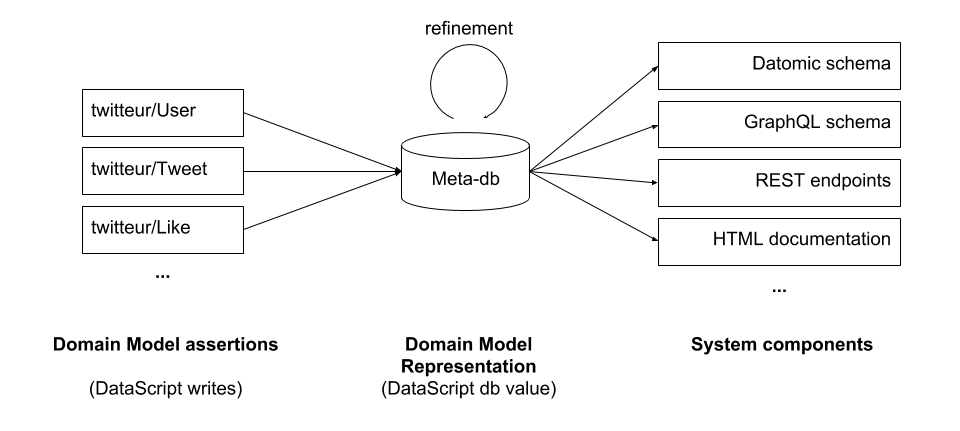
This post discusses an approach to application architecture using DataScript (an in-memory graph database, cf the annex). The idea is simply to store metadata representing the Domain Model of the application in a DataScript database, and automatically derive the 'machine' aspects of the system from that metadata.
If this is enough to give you inspiration for solving your own problems, my main goal for this article is already achieved. Read on for a more detailed discussion of how, why and when to apply this approach.
The approach
The Domain Model
Every application has some notion of a Domain Model, a system of abstractions and rules describing the reality that the system is meant to address. Domain Models can take many forms, but in this article what I'm calling the Domain Model is essentially what we put in a UML diagram representing a data schema.
As an example, imagine we're developing a tiny Twitter clone named Twitteur; we may represent our Domain Model for Twitteur like so:

Very typical stuff: we've defined a couple of Entity types (User and Tweet), each containing a few attributes, each attribute being annotated with a datatypes and various modifier, for instance:
user/emailis marked as private, which is in this case a security concern: it should not be publicly visible to users of the application.user/n_followersis in a light color to signify that it's derived, i.e computed from other attributes.
There is not enough information here to extract the nifty-gritty details of how the system should work; but it gives us an important overview of the domain concepts and rules underlying the system.
This Domain Model is quite small to keep the article readable, but you have to imagine the approach we're discussing here applied to dozens of Entity types and hundreds of attributes.
The 'Machine Aspects'
In application code, this Domain Model will typically be apparent in many different 'mechanical' aspects of our application, for instance:
- Database schema (SQL tables, Datomic attributes, ElasticSearch Mapping Types, etc.)
- Database queries
- API contracts (GraphQL schema, OpenAPI specification for REST APIs, etc.)
- Data validation / representation / packaging / transformation
- Enforcement of security rules
- Test data generation
That's what we call the 'machine aspects' of the system. In most systems, the code for these machine aspects has an (often implicit) dependency in the Domain Model: bits of the Domain Model are hardcoded in the middle of the 'Machine Aspects' code. Today, we're talking about doing something different: making the 'Machine-Aspects' code domain-agnostic, and parameterizing it with a representation of the Domain Model.
The problem
As I was growing a relatively large Clojure application over the course of several years, I noticed that adding any features resulted in a lot of redundancy, which required discipline to do right. For instance, adding a single Attribute required changes to Datomic schema installation transactions and to a GraphQL Field and to data validation schemas and to security rules etc. Forgetting to make any one of these changes would result in bugs, and was an easy error to make as these various aspects were neither colocated nor explicitly related in code.
This redundancy created more important problems than just increased volume of code:
- over-specificity: the same mechanical patterns got repeated again and again, resulting in a large surface area for bugs to appear (and therefore a large surface area to write tests for).
- implicit, scattered domain logic: when reading code, the core domain logic had essentially to be reverse-engineered from bits of mechanical code spread in several places in the codebase.
From domain representation to machine execution
So the idea I'm presenting here is simple:
- represent our Domain Model declaratively, as an in-program data structure (a 'meta-database').
- derive the 'machine' behaviour generically from this representation.
This means that your code will tend to be split in 2 parts - a declarative part specific to your domain, and a generic part implementing your system's machinery.
Your first instinct to implement step 1 may be to represent the Domain Model with common associative data structures: maps, lists, sets, etc. The problem with these is that you may have a hard time implementing step 2: you will need to query and navigate the Domain Model representation in non-trivial ways, to which the tree structure resulting from using maps and lists is not well suited. As we've seen in the UML diagram above, our Domain Model is more graph-like than tree-like.
Which brings me to the second point of this article: if you're going to have an in-program representation of the Domain Model, you might as well use DataScript as the supporting data structure (and API).
Enter DataScript
DataScript is an in-memory database / data-structure, available as a library on the JVM or JavaScript, which takes inspiration from the Datomic database. DataScript has many interesting characteristics, but here are the one that are relevant for this discussion:
- A flexible, graph-structured data model: the databased is logically made of a set of facts about entities (Entity-Attribute-Value triples), which naturally form a graph. Very little about the structure of that graph needs to be declared upfront; it doesn't have the rigid, statically-defined characteristics of tables in relational databases.
- Powerful read APIs: you can query a DataScript database using either Datalog (a declarative, logic-based query language, which expresses query clauses as pattern matching, as expressive as SQL), the Entity API (navigation through the database graph via a map-like interface) or the Pull API (pulling trees of data out of the database graph, similarly to GraphQL) - or any composition of those!
- Composable writes, expressed as ordinary data structures: write requests are expressed with lists and maps (not text like SQL), and it's very easy to make sophisticated writes out of simple ones specified independently, thanks to features like temporary ids and upserts which automatically bring together the pieces of the puzzle.
See the annex to get a quick tour of DataScript.
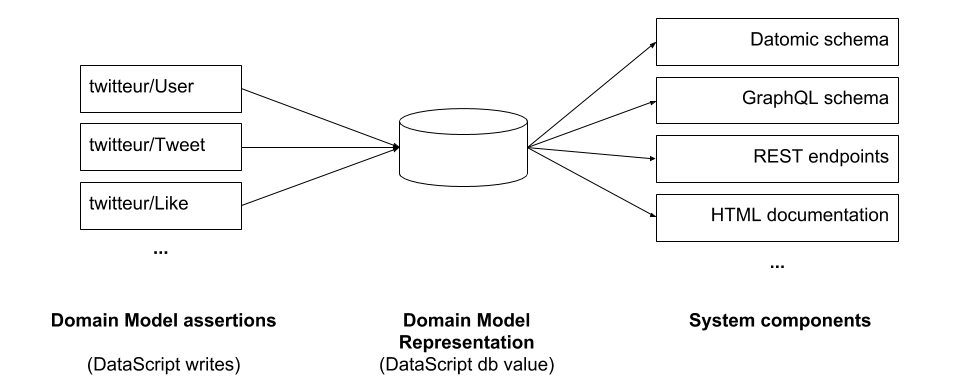
DataScript is commonly used to hold data in client-side applications, typically as part of a data-synchronization mechanism. What we're doing here is very different: we using it to hold meta-data about our Domain Model. Here's how it goes:
- We declare assertions about our Domain Model as DataScript writes (so, just data structures).
- We merge these Domain Model assertions into a DataScript database.
- We query this DataScript database to generate various system components (the 'machine aspects' mentioned above) - and also to inspect our Domain Model representation for day-to-day development.
Our Domain Model Assertions may look like this:
;;;; Model meta-data
;; These 2 values are DataScript Transaction Requests, i.e data structures defining writes to a DataScript database
;; NOTE in a real-world codebase, these 2 would typically live in different files.
(def user-model
[{:twitteur.entity-type/name :twitteur/User
:twitteur.schema/doc "a User is a person who has signed up to Twitteur."
:twitteur.entity-type/attributes
[{:twitteur.attribute/name :user/id
:twitteur.schema/doc "The unique ID of this user."
:twitteur.attribute/ref-typed? false
:twitteur.attribute.scalar/type :uuid
:twitteur.attribute/unique-identity true}
{:twitteur.attribute/name :user/email
:twitteur.schema/doc "The email address of this user (not visible to other users)."
:twitteur.attribute/ref-typed? false
:twitteur.attribute.scalar/type :string
:twitteur.attribute.security/private? true} ;; here's a domain-specific security rule
{:twitteur.attribute/name :user/name
:twitteur.schema/doc "The public name of this user on Twitteur."
:twitteur.attribute/ref-typed? false
:twitteur.attribute.scalar/type :string}
{:twitteur.attribute/name :user/follows
:twitteur.schema/doc "The Twitteur users whom this user follows."
:twitteur.attribute/ref-typed? true ;; this attribute is a reference-typed
:twitteur.attribute.ref-typed/many? true
:twitteur.attribute.ref-typed/type {:twitteur.entity-type/name :twitteur/User}}
{:twitteur.attribute/name :user/n_followers
:twitteur.schema/doc "How many users follow this user."
:twitteur.attribute/ref-typed? false
:twitteur.attribute.ref-typed/many? true
:twitteur.attribute.scalar/type :long
:twitteur.attribute/derived? true} ;; this attribute is not stored in DB
{:twitteur.attribute/name :user/tweets
:twitteur.schema/doc "The tweets posted by this user."
:twitteur.attribute/ref-typed? true
:twitteur.attribute.ref-typed/many? true
:twitteur.attribute.ref-typed/type {:twitteur.entity-type/name :twitteur/Tweet}
:twitteur.attribute/derived? true}
]}])
(def tweet-model
;; NOTE: to demonstrate the flexibility of DataScript, we choose a different but equivalent data layout
;; in this one, we define the Entity Type and the Attributes separately
[;; Entity Type
{:twitteur.entity-type/name :twitteur/Tweet
:twitteur.schema/doc "a Tweet is a short message posted by a User on Twitteur, published to all her Followers."
:twitteur.entity-type/attributes
[{:twitteur.attribute/name :tweet/id}
{:twitteur.attribute/name :tweet/content}
{:twitteur.attribute/name :tweet/author}
{:twitteur.attribute/name :tweet/time}]}
;; Attributes
{:twitteur.attribute/name :tweet/id
:twitteur.schema/doc "The unique ID of this Tweet"
:twitteur.attribute/ref-typed? false
:twitteur.attribute.scalar/type :uuid
:twitteur.attribute/unique-identity true}
{:twitteur.attribute/name :tweet/content
:twitteur.schema/doc "The textual message of this Tweet"
:twitteur.attribute/ref-typed? false
:twitteur.attribute.scalar/type :string}
{:twitteur.attribute/name :tweet/author
:twitteur.schema/doc "The Twitteur user who wrote this Tweet."
:twitteur.attribute/ref-typed? true
:twitteur.attribute.ref-typed/many? false
:twitteur.attribute.ref-typed/type {:twitteur.entity-type/name :twitteur/User}}
{:twitteur.attribute/name :tweet/time
:twitteur.schema/doc "The time at which this Tweet was published, as a timestamp."
:twitteur.attribute/ref-typed? false
:twitteur.attribute.scalar/type :long}])
As you see, these are just data structures, and you have a lot of flexibility in the shape and locations to define them.
Now, here's how you would merge them into a DataScript database:
;;;; Writing this metadata to a DataScript db
(require '[datascript.core :as dt])
(def meta-schema
{:twitteur.entity-type/name {:db/unique :db.unique/identity}
:twitteur.entity-type/attributes {:db/valueType :db.type/ref
:db/cardinality :db.cardinality/many}
:twitteur.attribute/name {:db/unique :db.unique/identity}
:twitteur.attribute.ref-typed/type {:db/valueType :db.type/ref
:db/cardinality :db.cardinality/one}})
(defn empty-model-db
[]
(let [conn (dt/create-conn meta-schema)]
(dt/db conn)))
(def model-db
"A DataScript database value, holding a representation of our Domain Model."
(dt/db-with
(empty-model-db)
;; Composing DataScript transactions is as simple as that: concat
(concat
user-model
tweet-model)))
We can now leverage all the power of DataScript to query our Domain Model, which makes it much easier to generate the 'machine-aspects' system components we need. Here's an example REPL session demonstrating this sort of queries:
;;;; Let's query this a bit
(comment
;; What are all the attributes names in our Domain Model ?
(sort
(dt/q
'[:find [?attrName ...] :where
[?attr :twitteur.attribute/name ?attrName]]
model-db))
=> (:tweet/author :tweet/content :tweet/id :tweet/time :user/email :user/follows :user/id :user/n_followers :user/name)
;; What do we know about :tweet/author?
(def tweet-author-attr
(dt/entity model-db [:twitteur.attribute/name :tweet/author]))
tweet-author-attr
=> {:db/id 10}
(dt/touch tweet-author-attr)
=>
{:twitteur.schema/doc "The Twitteur user who wrote this Tweet.",
:twitteur.attribute/name :tweet/author,
:twitteur.attribute/ref-typed? true,
:twitteur.attribute.ref-typed/many? false,
:twitteur.attribute.ref-typed/type {:db/id 1},
:db/id 10}
(-> tweet-author-attr :twitteur.attribute.ref-typed/type dt/touch)
=>
{:twitteur.schema/doc "a User is a person who has signed up to Twitteur.",
:twitteur.entity-type/attributes #{{:db/id 4} {:db/id 6} {:db/id 3} {:db/id 2} {:db/id 5}},
:twitteur.entity-type/name :twitteur/User,
:db/id 1}
;; What attributes have type :twitteur/User?
(dt/q '[:find ?attrName ?to-many? :in $ ?type :where
[?attr :twitteur.attribute.ref-typed/type ?type]
[?attr :twitteur.attribute/name ?attrName]
[?attr :twitteur.attribute.ref-typed/many? ?to-many?]]
model-db [:twitteur.entity-type/name :twitteur/User])
=> #{[:tweet/author false] [:user/follows true]}
;; What attributes are derived, and therefore should not be stored in the database?
(->>
(dt/q '[:find [?attr ...] :where
[?attr :twitteur.attribute/derived? true]]
model-db)
(map #(dt/entity model-db %))
(sort-by :twitteur.attribute/name)
(mapv dt/touch))
=>
[{:twitteur.schema/doc "The tweets posted by this user.",
:twitteur.attribute/derived? true,
:twitteur.attribute/name :user/follows,
:twitteur.attribute/ref-typed? true,
:twitteur.attribute.ref-typed/many? true,
:twitteur.attribute.ref-typed/type {:db/id 7},
:db/id 5}
{:twitteur.schema/doc "How many users follow this user.",
:twitteur.attribute/derived? true,
:twitteur.attribute/name :user/n_followers,
:twitteur.attribute/ref-typed? false,
:twitteur.attribute.ref-typed/many? true,
:twitteur.attribute.scalar/type :long,
:db/id 6}]
;; What attributes are private, and therefore should not be exposed publicly?
(set
(dt/q '[:find [?attrName ...] :where
[?attr :twitteur.attribute.security/private? true]
[?attr :twitteur.attribute/name ?attrName]]
model-db))
=> #{:user/email}
)
As an example, here's what generating a GraphQL schema could look like (for the Lacinia library, which is a Clojure GraphQL wrapper).
It's really important to understand that the DataScript database value is not a hidden implementation detail here: the database is the API. Not only is our Domain Model programmatically accessible, but we didn't even have to make a custom API for it: we already have the DataScript query API for that. This makes our Domain Model Representation both a good programming substrate and an effective communication medium.
To make your system more transparent you may want to add another 'refinement' step before generating the system components, which consists of enriching the meta-database with facts about the Machine Aspects. This way, you can even query the meta-database about how your Domain Model got translated into system components. The logic for this refinement step is quite reminiscent of deductive rule engines - for instance "if an Attribute A is not derived, then there is a Datomic schema transaction for an attribute of the same type as A".
Finally, as you may have noticed, our Domain Model assertions code above is quite verbose and difficult to read. You may get around this issue by generating appropriate visualizations from the meta-database (e.g HTML pages or GraphViz); but it's also quite straightforward to make a small ad hoc DSL to make the code more concise and contrasted:
;;;; Let's make our schema code more readable,
;;;; by using some concision helpers
(require '[twitteur.utils.model.dml :as dml])
(def user-model
[(dml/entity-type :twitteur/User
"a User is a person who has signed up to Twitteur."
{:twitteur.entity-type/attributes
[(dml/scalar :user/id :uuid (dml/unique-id) "The unique ID of this user.")
(dml/scalar :user/email :string (dml/private) "The email address of this user (not visible to other users).")
(dml/scalar :user/name :string "The public name of this user on Twitteur.")
(dml/to-many :user/follows :twitteur/User "The Twitteur users whom this user follows.")
(dml/scalar :user/n_followers :long (dml/derived) "How many users follow this user.")
(dml/to-many :user/tweets :twitteur/Tweet (dml/derived) "The tweets posted by this user.")
]})])
(def tweet-model
[(dml/entity-type :twitteur/Tweet
"a Tweet is a short message posted by a User on Twitteur, published to all her Followers."
{:twitteur.entity-type/attributes
[(dml/scalar :tweet/id :uuid "The unique ID of this Tweet" (dml/unique-id))
(dml/scalar :tweet/content :string "The textual message of this Tweet")
(dml/to-one :tweet/author :twitteur/User "The Twitteur user who wrote this Tweet.")
(dml/scalar :tweet/time :long "The time at which this Tweet was published, as a timestamp.")
]})])
;; Note that there's no macro magic above: user-model and tweet-model are still plain data structures,
;; we just use the dml/... functions to assemble them in a more readable way.
;; In particular, you can evaluate any sub-expression above in the REPL and see exactly
;; how it translates to a data structure.
The dml/... helper functions used in the above snippet are defined here.
Tradeoffs and limitations
Now that we've described the approach, the question that remains is: 'Should I adopt it?'. We'll discuss this question from a few different perspectives.
Prior art
The idea of writing a representation of the Domain Model in declarative form and automatically deriving machine behaviour from that is not new. There's a number of popular solutions in the industry in which this idea is embodied:
- Database DMLs (Data Modeling Languages) e.g in SQL: you describe the shape of your data, and sometimes can query it.
- ORMs (Object-Relational Mappers) like ActiveRecord / Hibernate, and more generally class-based frameworks: you represent your 'model' as a class and use class annotations or various metaprogramming features to make your Domain Model assertions
- API schemas, like GraphQL schemas for GraphQL, OpenAPI for REST and WSDL for SOAP, also rely on a data representation of some part of your Domain Model
I see a number of drawbacks to using these solutions as the representation for your Domain Model.
First, they tend to have a very biased and incomplete perspective of your system. ORMs and DMLs only talk about your domain in the perspective of data persistence and integrity; API schemas only talk about your domain in the perspective of data exchange and validation. I think you lose many benefits of the Domain-Model-in-program approach once your representation stops being all-encompassing.
Second, they tend to be not very programmable, especially class-based tools like ORMs. They're usually not portable across runtimes (e.g accessible to both client and server code), they don't offer the composable, data-based writes and powerful querying features of DataScript, and are usually not open to extensions.
Third, and related to programmability, they often are not very transparent or tangible. When you write annotations in a class, you don't get a query API to inspect / explore the implications of that annotation; all you get to do is read the documentation and / or reverse-engineer them from the external behaviour of the system. In particular, even if your framework provides useful logic to process your Domain Model assertions, you can't really reuse nor rely on that logic to complement that framework for your own needs.
Finally, I think that these frameworks, because of their genericity, suffer from the fundamental limitation that they don't know and cannot know the language of your domain, nor its implications on your software system. These frameworks enable your to address machine aspect with a domain-first approach, but as a byproduct they impose on you a representation of your Domain Model, and assumptions about the implications in terms of machine aspects. The more advanced your system, the more likely it is that your framemork of choice will be a misfit for it. You don't have this problem with DataScript, which only imposes a representation medium for your Domain Model - one that offers a lot of leverage and few constraints, as we've seen.
Plumbing-first vs Domain-first
I think there are essentially 2 approaches to developing software, each with their own merits, which I'd call plumbing-first and domain-first.
Plumbing-first consists of programming by starting with 'mechanical' components - HTTP routes, database queries, etc. - shaping them until the program's behaviour meets the requirements of the Domain.
A plumbing-first approach makes for early successes, and is generally a good approach when the Domain is not well-known or very simple. Of course, the downside is accidental complexity, as well as the problems we mentioned above such as over-specificity and an implicit, scattered domain model.
Domain-first consists of programming by coding a declarative representation of the Domain Model, then building a generic interpreter (in the broad sense - you don't have to create a new programming language for that) which executes that representation.
A domain-first approach has the advantage of keeping the domain-specific code focused on the essential, and of making the machine-specific code relatively concise and very generic, but alse more abstract; in particular, you are combatting complexity by adopting home-made abstractions, and that means that the development team must be willing to learn new abstractions.
The approach we're describing is this article is definitely domain-first.
Adaptable vs Principled
In his excellent book Elements of Clojure, Zach Tellman draws a distinction between principled and adaptable systems of abstractions:
We can build a principled system, which enforces predictable relationships between its abstractions. Alternately, we can build an adaptable system, which has sparse and flexible relationships between its abstractions.
In his talk On Abstraction, Zach Tellman then presents the following tradeoffs to principled or adaptable systems:

My understanding of this is that the approach discussed in this article is principled. We gain predictability and save work by enforcing an organizing principle about how our Domain Model should be expressed and interpreted, while making a strong assumption of regularity in our domain requirements.
Zach Tellman suggests that we can cope with the brittleness of principled components by embedding them in an adaptable 'framework' or 'glue', and in particular by leaving some space between principled components and the periphery of our systems. You should leave 'escape hatches' for edge cases where your Domain Model representation becomes insufficient; for instance, you should preserve the ability to exceptionally define some GraphQL fields or database attributes or REST endpoints without going through your Domain Model representation.
You're in the business of framework-authoring
The way I see it, if you're adopting the approach described in this post, you're going down the road of building a homemade framework. That's not necessarily a bad thing, because your homemade framework makes assumptions that are by definition aligned with your use case, and it doesn't need to have the crazy ambitions of the more popular frameworks we see out there (for instance, it doesn't have to pretend to solve the Object-Relational Impedance Mismatch, or reinvent the web, or try to hide distributed system issues behind method calls, etc.)
By 'framework', I really mean a set of programmatically-enforced decisions about application architecture. In this sense, I think making your own framework is viable if you don't try to solve impossible problems, and don't make your assumptions too broad. In particular, as you can see, I'm not offering any library to embody the approach described in this post, because I think it would do more harm than good: the entire point is that you, only you, can know how your system should be described in domain terms.
Still, even if it pays on the long-term, making a framework is not a light endeavour, and if you're going to do it at all you should do it thoroughly:
- Think it through
- Test it well
- Document it well. In particular, it's incredibly easy to generate HTML documentation (à la JavaDoc) from a DataScript-backed meta-database. This can be a effective strategy to make documentation that is less likely to become stale, and uses your Domain Model as its own example, making it more accessible to newcomers.
Experience report: BandSquare
BandSquare is a SaaS platform for creating and analyzing marketing campaigns and surveys. We have applied this approach to BandSquare's backend code for more than 18 months now; at the time of writing, our Domain Model Representation features over 80 Entity Types and 450 Attributes. The main Machine Aspects we address are generating GraphQL(ish) schema and handlers, Datomic schema transactions, security rules, and documentation; we're considering adding more, such as change detection for ETL.
Overall, this approach has been a significant improvement to BandSquare's development. We've found that:
- BandSquare's domain of a 'platform' is a good fit for this approach, as we want to extend the platform to new use cases while leveraging as much of the existing code as possible.
- The fact that Datomic and GraphQL are conceptually close has been quite helpful in implementing it.
Annex: a DataScript refresher
DataScript is an in-memory data structure, with similar read and write APIs to a Datomic database. As such, DataScript can be compared to other collections:

With that in mind, check out this DataScript Demo to get a better understanding of how DataScript works.