Datomic: Event Sourcing without the hassle
- Why Event Sourcing?
- How Event Sourcing is usually done
- Difficulties of conventional Event Sourcing
- Designing Event Types and Event Handlers is hard work
- Detecting indirect changes is still hard
- Transactionality is difficult to achieve
- Conflating Commands and Events
- How Datomic does it
- Conclusion
- See also
When I got started using the Datomic database, I remember someone describing it to me as 'Event Sourcing without the hassle'. Having built Event Sourcing systems both with and without Datomic, I think this is very well put, although it might not be obvious, especially if you don't have much experience with Datomic.
In this article, we'll describe briefly what Event Sourcing is, how it's conventionally implemented, analyze the limitations of that, and contrast that with how Datomic enables you to achieve the same benefits. We'll see that, for most use cases, Datomic enables us to implement Event Sourcing with much less effort, and (more importantly) with more agility. By which I mean: less anticipation / planning
Note: I'm not affiliated to the Datomic team in any way other than being a user of Datomic.
Why Event Sourcing?
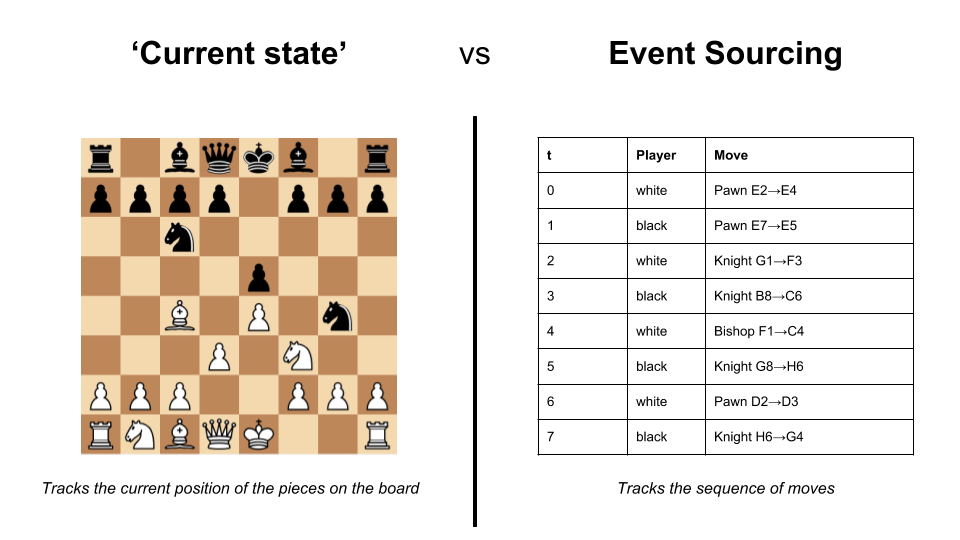
As of today, most information systems are implemented with a centralized database storing the 'current state' (or you might say 'current knowledge') of the system. This database is usually a big mutable shared data structure, supported by database systems such as PostgreSQL / MongoDB / ElasticSearch / ... or a combination of those.
For instance, a Q&A website such as StackOverflow could be backed with a SQL database, with tables such as Question, Answer, User, Comment, Tag, Vote etc.
When all the data you have is about the 'current state' of the system, you can only ask questions about the present (Examples: "What's the title of Question 42?" / "Has User 23 answered Question 56?" / etc.). But it turns out you may have important questions that are not about the present:
- How did we get there? What's the sequence of events which led you to the current state? This is useful for audit trails, analytics, etc. (Example: "How many times times do Users typically change the content of a Question?")
- How was the state previously? Especially useful for investigating bugs. (Example: "What were the Tags associated with Question 38 last Monday at 6:23pm?")
- What changed recently? Useful for reacting to change, and in particular for propagating novelty. (Examples: "What Questions have been affected by changes (directly or not) in the last 6 hours?" / "What events have caused the Reputation of User 42 to evolve in the last minute?")
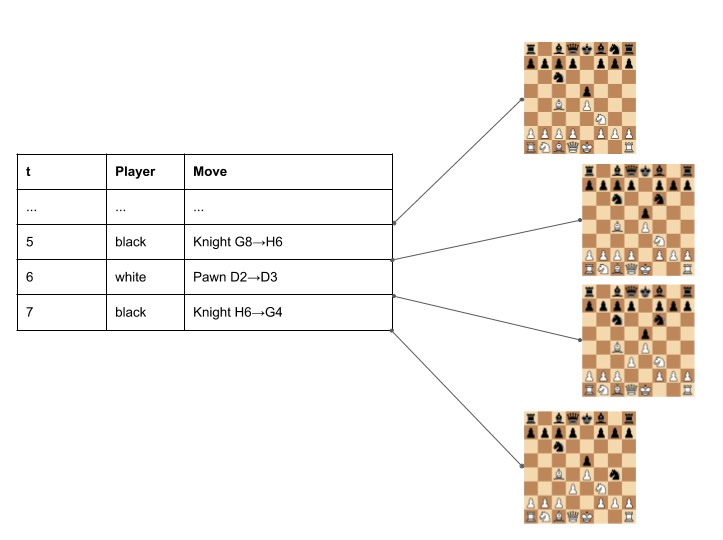
Event Sourcing is an architectural approach designed to address such questions. Event Sourcing consists of keeping track not of the current state, but of the entire sequence of state transitions which led to it. These state transitions are called Events, and are the "source of truth" of the system, from which the current state (or any past state) is inferred (hence the name Event Sourcing).
The sequence of events is stored in an Event Log, and it's important to understand that this Event Log is accumulate-only: events are (normally) only ever appended to the Log, never modified or erased.
Benefits of Event Sourcing:
- You don't lose information (since you only ever add to the data you have already written); in particular, it's possible to reproduce a past state of the system.
- Data synchronization is easier: since you can determine what data has been recently added, you can propagate novelty to other components of the system, which lets you build materialized views (e.g representing your data in search or analytics-optimized query engines such as ElasticSearch), send notifications (e.g to a browser UI), etc.
How Event Sourcing is usually done
At the time of writing, the conventional way of implementing Event Sourcing is as follows:
- You design a set of Event Types suited to your domain. (For instance:
UserCreatedQuestion,UserUpdatedQuestion,UserCreatedAnswer,UserVotedOnQuestion, etc.). - Each Event is a record containing an Event Type, a timestamp (when it was added to the Log), and data attributes specific to that Event Type (e.g
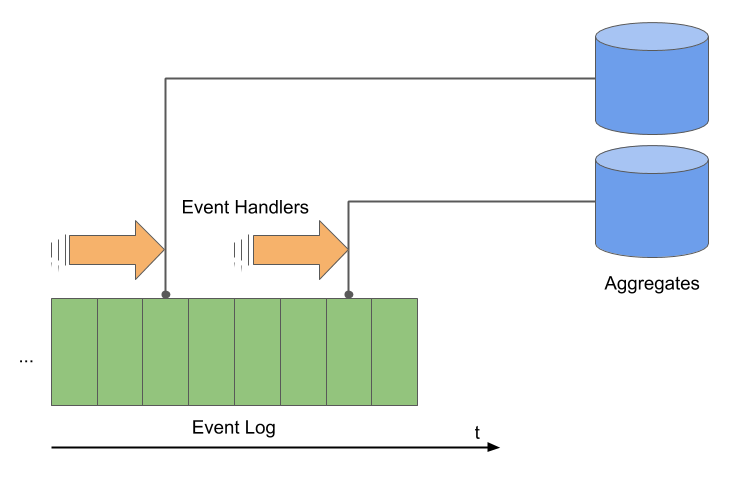
question_id,user_idetc.). - Downstream of the Event Log, events are processed by Event Handlers to maintain Aggregates of the data (for instance, a document store containing one document per Question), or trigger Reactions to events (e.g sending an email to a User when one of her questions was answered). Importantly, for technological reasons, this processing of events is typically asynchronous, with the implication that the Aggregates are at best eventually consistent with the Log (Aggregates "lag behind" the Log).
Back to our Q&A example, here's what some events could look like in EDN format:
({:event_type :UserCreatedQuestion
:event_time #inst "2018-11-07T15:32:09"
:user_id "jane-hacker3444"
:question_id "what-is-event-sourcing-3242599"
:question_title "What is Event Sourcing"
:question_body "I've heard a lot about Event Sourcing but not sure what it's for exactly, could someone explain?"
:question_tags ["Programming"]}
;; ...
{:event_type :UserUpdatedQuestion
:event_time #inst "2018-11-07T15:32:54"
:user_id "jane-hacker3444"
:question_id "what-is-event-sourcing-3242599"
:question_title "What is Event Sourcing?"}
;; ...
{:event_type :UserCreatedAnswer
:event_time #inst"2018-11-08T14:16:33.825-00:00"
:user_id "alice-doe32099"
:question_id "what-is-event-sourcing-3242599"
:answer_id #uuid"af1722d5-c9bb-4ac2-928e-cf31e77bb7fa"
:answer_body "Event Sourcing is about [...]"}
;; ...
{:event_type :UserVotedOnQuestion
:event_time #inst"2018-11-08T14:19:31.855-00:00"
:user_id "bob980877"
:question_id "what-is-event-sourcing-3242599"
:vote_direction :vote_up})
In this sequence of events, User "jane-hacker3444" created a Question about Event Sourcing, then updated it, presumably to correct its title. User "alice-doe32099" then created an Answer to that Question, and User "bob980877" upvoted the Question.
This could feed an Aggregate representing questions as JSON-like documents, such as:
{
"question_id": "what-is-event-sourcing-3242599",
"question_title": "What is Event Sourcing?",
"question_body": "I've heard a lot about Event Sourcing but not sure what it's for exactly, could someone explain?",
"question_tags ":["Programming"],
"question_n_upvotes": 1,
"question_n_downvotes": 0,
"question_author": {
"user_id": "jane-hacker3444",
"user_name": "Jane P. Hacker",
"user_reputation": 32342
},
"question_answers": [{
"answer_id": "af1722d5-c9bb-4ac2-928e-cf31e77bb7fa",
"answer_body": "Event Sourcing is about [...]",
"answer_author": {
"user_id": "alice-doe32099",
"user_name": "Alice Doe",
"user_reputation": 12665
}
}]
}
Difficulties of conventional Event Sourcing
Regardless of the implementation technologies used (EventStore / Kafka / plain old SQL...), common difficulties arise from the 'conventional Event Sourcing' approach described above. We'll try to categorize them in this section.
Designing Event Types and Event Handlers is hard work
Case study: the many ways to update a Question
You're designing the initial version of the Q&A website, and wondering what the proper Event Types should be for updating Questions. You're thinking UserUpdatedQuestion, but maybe that's not granular enough? Should it be the finer-grained UserUpdatedQuestionTitle? But then maybe that'd make too many Event Types to handle, and implementing the Event Handlers will take forever? Should you opt for the more general UserUpdatedFieldOfEntity, but then the Log will become harder to make sense of? Also, since a Question may be changed by someone else than her author, maybe QuestionTitleChanged is a better way to go... but then , how do you track that the action was caused by a User?
[...]
6 months later, the system is in production. Tom, the Key Account Manager, bursts into your office. "So, there's this high-profile expert I convinced to come answer one of the popular questions, in exchange for an exceptional gift of 500 points of reputation; could you make that happen for tonight?" You think for a minute. There's no Event type for exceptional changes to reputation. "I'm sorry," you reply. "For now it's impossible to change the reputation of a User without it coming from votes. We'd need to make a specific development."
In the good old days of the 'current state in one database' approach, all you had to do was design a suitable representation for your state space, and then you had all the power of a query language to navigate in that space. For example, in a relational database, you would declare a set of tables and columns, and then you had all the power of SQL to change the data you stored.
Life is not so easy with conventional Event Sourcing, because you have to anticipate every change you're going to want to apply to your state, design an Event Type for it, and implement the Event Handlers for this Event Type. Ad hoc writes are especially difficult, because any new way to write calls for new code.
What's more, naming, granularity and semantics are hard to get right when designing Event Types - and you had better get that right in the first place, because unless you rewrite your Event Log any Event Type will have to be processed by your Event Handlers for the entire lifetime of your codebase (since re-processing the entire Log is assumed to be a frequent operation). Too many Event Types may result in more work for implementing Event Handlers; on the other hand, coarse-grained Event Types are less reusable.
I think the lesson here is that an enumeration of application-defined Event Types is a weak language for describing change.
Detecting indirect changes is still hard
Case study: linking Question upvotes to User reputation
You're writing the Event Handler for an Aggregate that keeps track of the reputation score of each User: it's a basic key-value store that associates each user_id to a number. In particular, each time there's an upvote on a Question, it must increment the reputation of the Question's author. The problem is, in its current form, the UserVotedOnQuestion Event Type does not contain the user_id of the Question's author, only the id of the Question...
What should you do?
- Should you change the
UserVotedOnQuestionEvent Type so that it explicitly contains the id of the author? But that would be redundant, and then who knows how many more things you will want to add later to the Event Types, as you make new Aggregates? - Should you change the Aggregate so that it also keeps track of the Question -> User relationship? But that would make it more complex, and is likely to be redundant with the work of other Aggregates...
An Event Log gives you precise data about what changed between 2 points in time; but that does not mean that data is trivially actionable. To update an Aggregate based on an Event, you need to compute if and how the Event affects the Aggregate. When dealing with a relational information model, an Event may be about some entity A and indirectly affect another Entity B, but the relationship between A and B is not apparent in the Event; in the above example, an Event of type UserVotedOnQuestion affects a User entity without directly referencing it. We need query power to determine how an Event affects the downstream Aggregates, but an Event Log on its own offers very little query power.
There are several strategies to mitigate this problem, all with important caveats:
- You can 'denormalize' the Event Types to add more data to them, effectively doing some pre-computations for the Aggregates. This means the code that produces the Events needs to anticipate all the ways in which the Events will be consumed - the sort of coupling we're trying to get away from with Event Sourcing.
- You can enrich each Aggregate to keep track of relational information it needs. This makes Event Handlers more complex to implement, and potentially redundant.
- You can add an 'intermediary' Aggregate that only keeps track of relational information and produces a stream of 'enriched' Events. This is probably better than both solutions above, but it still takes work, and it still needs to be aware of the needs of all downstream Aggregates.
Transactionality is difficult to achieve
Case study: preventing double Answers
You're investigating a bug of the Q&A website: some User managed to create 2 Answers to a Question, which is not supposed to happen... Indeed, when a User tries to create the Answer, the code checks via the QuestionsById Aggregate that this User has not yet created an Answer to this Question, and no UserCreatedAnswer Event is emitted if that check fails.
You then realize this is caused by a race condition: between the time the 1st Answer was added to the Log and the time it made its way into the QuestionsById Aggregate, the 2nd Answer was added, thus passing the check...
'Great', you think. 'I love debugging concurrency issues.'
Some programs consist only of aggregating information from various data sources, and presenting this information in a new way; analytics dashboards and accounting systems are examples of such programs. Event Sourcing is relatively easy to implement for those. But most systems can't be described so simply. When you buy something on an e-commerce website, you don't just inform them that you are buying something; you request them to make a purchase, and if your payment information is correct and the inventories are not exhausted, then the e-commerce decides to create an order. Even basic administration features can be enough to get you out of the 'only aggregating information' realm.
Here we see arise the need for transactions, and that's the catch: transactions are hardly compatible with eventually consistent writes, which is what you get by default when processing the Event Log asynchronously.
You can mitigate this issue by having an Aggregate which is updated synchronously with the Event Log. This means adding an Event is no longer as simple as appending a data record at the end of a queue: you must atomically do that and update some queryable representation of the current state (e.g a relational database).
It's also important to realize that transactions are not just for allowing Events into the Log, but also for computing them. For instance, when you order a ticket for a show online, the ticketing system must consult the inventory and choose a seat number for you (even if it's just for adding it to your cart, it must happen transactionally). Which leads us to the distinction between Commands and Events.
Conflating Commands and Events
In conventional Event Sourcing, another common approach for addressing the transactionality issues outlined above is to add another sort of Events, which request a change without committing to it. For instance, you could add a UserWantedToCreateAnswer Event, which later on will be processed by an Event Handler that will emit either a UserCreatedAnwser Event or an EventCreationWasRejected Event and add it to the Log; this Event Handler will of course need to maintain an Aggregate to keep track of Answer creations.
This approach has the advantage of freeing you from some race conditions, but it adds significant complexity. Handling events is now side-effectful and cannot be idempotent. Since those special new Events should be handled exactly once, you will have to be careful when re-processing the Log (see Martin Fowler's article on Event Sourcing for more details on these caveats). Finally, this means you're forcing an asynchronous workflow on the producers of these Events (as in: "Hey, thank you for submitting this form, unfortunately we have no idea if and when your request will be processed. Stay tuned!").
To me, this complexity arises from the fact that conventional Event Sourcing tempts you to forget the essential distinctions between Commands and Events. A small refresher about these notions:
- A Command is a request for change. It's usually formulated in the imperative mood (e.g
AddItemToCart). You typically want them to be ephemeral and processed exactly once. - An Event, as we already mentioned, describes a change that happened. It's usually formulated in the past tense and indicative mood (e.g
ItemAddedToCart). You typically want them to be durable, and processed as many times as you like. - From this perspective, a transactional engine is a process which turns Commands into Events.
Commands and Events play very different roles, and it's no surprise that conflating them results in complexity.
How Datomic does it
Datomic's model
(See also the official documentation).
Datomic models information as a collection of facts. Each fact is represented by a Datom: a Datom is a 5-tuple [entity-id attribute value transaction-id added?], in which:
entity-idis an integer identifying the entity (e.g a User or a Question) described by the fact (akin to a row number in a relational database)attributecould be something like:user_first_nameor:question_author(akin to a column in a relational database)valueis the 'content' of the attribute for this entity (e.g"John")transaction-ididentifies the transaction at which the datom was added (a transaction is itself an entity)added?is a boolean, determining if the datom is added (we now know this fact) or retracted (we no longer know this fact)
For instance, the Datom #datom [42 :question_title "What is Event Sourcing" 213130 true] could be translated in English: "We learned from Transaction 213130 that Entity 42, which is a Question, has title 'What is Event Sourcing"'.
A Datomic Database Value represents the state of the system at a point in time, or more accurately the knowledge accumulated by the system up to a point in time. From a logical standpoint, a Database value is just a collection of Datoms. For instance, here's an extract of our Q&A database:
(def db-value-extract
[;; ...
#datom [38 :user_id "jane-hacker3444" 896647 true]
;; ...
#datom [234 :question_id "what-is-event-sourcing-3242599" 896770 true]
#datom [234 :question_author 38 896770 true]
#datom [234 :question_title "What is Event Sourcing" 896770 true]
#datom [234 :question_body "I've heard a lot about Event Sourcing but not sure what it's for exactly, could someone explain?" 896770 true]
;;
#datom [234 :question_title "What is Event Sourcing" 896773 false]
#datom [234 :question_title "What is Event Sourcing?" 896773 true]
;; ...
#datom [456 :answer_id #uuid"af1722d5-c9bb-4ac2-928e-cf31e77bb7fa" 896789 true]
#datom [456 :answer_question 234 896789 true]
#datom [456 :answer_author 43 896789 true]
#datom [456 :answer_body "Event Sourcing is about [...]" 896789 true]
;; ...
#datom [774 :vote_question 234 896823 true]
#datom [774 :vote_direction :vote_up 896823 true]
#datom [774 :vote_author 41 896823 true]
;; ...
])
In practice, a Datomic Database Value is not implemented as a basic list; it's a sophisticated data structures comprising multiple indexes, which allows for expressive and fast queries using Datalog, a query language for relational data. But logically, a Database value is just a list of datoms. Surprisingly, this very simple model allows for representing and querying data no less effectively than conventional databases (SQL / document stores / graph databases /etc.).
A Datomic deployment is a succession of (growing) Database Values. Writing to Datomic consists of submitting a Transaction Request (a data structure representing the change that we want applied); this Transaction Request gets applied to the current Database value, which consists of computing a set of Datoms to add to it (a Transaction), thus yielding the next Database Value.
For instance, a Transaction Request for changing the title of a Question could look like this:
(def tx-request-changing-question-title
[[:db/add [:question_id "what-is-event-sourcing-3242599"] :question_title "What is Event Sourcing?"]])
This would result in a Transaction, where we recognize some Datoms of db-value-extract above:
(comment "Writing to Datomic"
@(d/transact conn tx-request-changing-question-title)
=> {:db-before datomic.Db @3414ae14 ;; the Database Value to which the Transaction Request was applied
:db-after datomic.Db @329932cd ;; the resulting next Database Value
:tx-data ;; the Datoms that were added by the Transaction
[#datom [234 :question_title "What is Event Sourcing" 896773 false]
#datom [234 :question_title "What is Event Sourcing?" 896773 true]
#datom [896773 :db/txInstant #inst "2018-11-07T15:32:54" 896773 true]]}
)
Now we start to see the deep similarities between Datomic and the Event Sourcing notions we've laid out so far:
- Transaction Requests correspond to Commands
- Transactions correspond to Events
- a Datomic database corresponds to an Event Log
We also see some important differences:
- Events consist of a combination of fine-grained Datoms; there is no Event Type with a prescribed structure.
- Events are directly not produced by application code; Transaction Requests (Commands) are.
Processing Events with Datomic
We'll now study how we can implement an Event Sourcing system with Datomic.
First, let's note that a Datomic Database Value can be viewed as an Aggregate; one that is maintained synchronously with no extra effort, contains all of the data stored in Events, and can be queried expressively. This Aggregate will probably cover most of your querying needs; from what I've seen, the most likely use cases for adding downstream Aggregates are search, low-latency aggregations, and data exports.
It's also worth noting that you can obtain any past value of a Datomic Database, and so you can reproduce a past state out-of-the-box - no need to re-process the entire Log:
(def db-at-last-xmas
(d/as-of db #inst "2017-12-25"))
You can use the Log API to get the Transactions between 2 points in time:
(comment "Reading the changes between t1 and t2 as a sequence of Transactions:"
(d/tx-range (d/log conn) t0 t1)
=> [{:tx-data [#datom [234 :question_id "what-is-event-sourcing-3242599" 896770 true]
#datom [234 :question_author 38 896770 true]
#datom [234 :question_title "What is Event Sourcing" 896770 true]
#datom [234 :question_body "I've heard a lot about Event Sourcing but not sure what it's for exactly, could someone explain?" 896770 true]
#datom [896770 :db/txInstant #inst "2018-11-07T15:32:09"]]}
;; ...
{:tx-data [#datom [234 :question_title "What is Event Sourcing" 896773 false]
#datom [234 :question_title "What is Event Sourcing?" 896773 true]
#datom [896773 :db/txInstant #inst "2018-11-07T15:32:54"]]}
;; ...
{:tx-data [#datom [456 :answer_id #uuid"af1722d5-c9bb-4ac2-928e-cf31e77bb7fa" 896789 true]
#datom [456 :answer_question 234 896789 true]
#datom [456 :answer_author 43 896789 true]
#datom [456 :answer_body "Event Sourcing is about [...]" 896789 true]
#datom [896789 :db/txInstant #inst"2018-11-08T14:16:33.825-00:00"]]}
;; ...
{:tx-data [#datom [774 :vote_question 234 896823 true]
#datom [774 :vote_direction :vote_up 896823 true]
#datom [774 :vote_author 41 896823 true]
#datom [896823 :db/txInstant #inst"2018-11-08T14:19:31.855-00:00"]]}]
)
Notice that, although they describe change in a very minimal form, Transactions can be combined with Database Values to compute the effect of a change in a straightforward way. You don't need to 'enrich' your Events to make them easier to process; they are already enriched with entire Database Values.
The best of both worlds: you get both absolute and incremental views of the state at each transition.For instance, here's a query that determines which Users must have their reputation re-computed because of Votes:
(comment "Computes a set of Users whose reputation may have been affected by Votes"
(d/q '[:find [?user-id ...]
:in $ ?log ?t1 ?t2 ;; query inputs
:where
[(tx-ids ?log ?t1 ?t2) [?tx ...]] ;; reading the Transactions
[(tx-data ?log ?tx) [[?vote ?a ?v _ ?op]]] ;; reading the Datoms
[?vote :vote_question ?q] ;; navigating from Votes to Questions
[?q :question_author ?user] ;; navigating from Questions to Users
[?user :user_id ?user-id]]
db (d/log conn) t1 t2)
=> ["jane-hacker3444"
"john-doe12232"
;; ...
]
;; Now it will be easy to update our 'UserReputation' Aggregate
;; by re-computing the reputation of this (probably small) set of Users.
)
When it comes to change detection, the basic approach described in the above example gets you surprisingly far. However, sometimes, you don't just want to know what changed: you want to know why or how it changed. For instance:
- you may want to keep track of what User caused the change
- you may want to know from what UI action the change originated
The recommended way to do that with Datomic is using Reified Transactions: Datomic Transactions being Entities themselves, you can add facts about them. For example:
(comment "Annotating the Transaction"
@(d/transact conn
[;; Fact about the Question
[:db/add [:question_id "what-is-event-sourcing-3242599"] :question_title "What is Event Sourcing?"]
;; Facts about the Transaction
[:db/add "datomic.tx" :transaction_done_by_user [:user_id "jane-hacker3444"]]
[:db/add "datomic.tx" :transaction_done_via_ui_action :UserEditedQuestion]])
=> {:db-before datomic.Db@3414ae14
:db-after datomic.Db@329932cd
:tx-data
[#datom [234 :question_title "What is Event Sourcing" 896773 false]
#datom [234 :question_title "What is Event Sourcing?" 896773 true]
#datom [896773 :db/txInstant #inst "2018-11-07T15:32:54" 896773 true]
#datom [896773 :transaction_done_by_user 38 896773 true]
#datom [896773 :transaction_done_via_ui_action :UserEditedQuestion 896773 true]]}
)
Cost-benefit analysis
Whether or not the usage of Datomic we described is 'true Event Sourcing' depends on your definition of Event Sourcing; but what's more important in my opinion is whether or not we get the benefits, and at what cost.
So let's revisit the objectives and common difficulties of Event Sourcing that we described above.
Do we get the benefits of Event Sourcing?
Yes:
- All state transitions are described in a Log of Events (accessible by Datomic's Log API)
- We have a high query power (Datalog) to consume that Log of Events and derive Aggregates from it
- We get a rich default Aggregate (Datomic database values) for free, with which we can reproduce past states out-of-the-box (
db.asOf(t)).
Do we still have the difficulties of conventional Event Sourcing?
Well, let's see:
- 'Designing Event Types and Event Handlers is hard': we don't design Event Types any more; we design only our database schema (which tends to map naturally to our domain model), and Datomic will do the work of describing changes in terms of Datoms, which can be handled generically. For the few cases where that description is not enough, we can extend it using Reified Transactions. Regarding Event Handlers, a lot of them are no longer needed because we have a good enough default Aggregate (Database Values).
- 'Detecting indirect changes is hard': it's now straightforward to compute the effects of each change on downstream Aggregates, since we have both incremental and global views of each state transition (Transactions and Database Values) with high query power.
- 'Transactionality is hard to achieve': no issues there, Datomic is fully ACID with an expressive language for writes.
- 'Conflating Commands and Events': there's not really room for confusion here - Datomic does not let us even emit Events, we can only write with Commands.
Of course, Datomic has limitations, and to get those benefits you have to make sure these limitations are not prohibitive for your use case:
- Write scale: Don't expect to make tens of thousands of writes per seconds on one Datomic system. (Read scale is okay. Datomic scales horizontally for reads, and hopefully this article has made it clear that it's easy to offload reads to specialized stores.)
- Dataset size: If you need to store petabytes of data, you will need to either complement or replace Datomic with something else.
- Data model: You data must lend itself well to being represented in Datomic. Datomic's Universal Schema, inspired by RDF, is good at modeling what you would store in table, document or graph-oriented databases, but with some imagination you could probably come up with something that's hard to represent in Datomic. (By the way, contrary to popular belief, Datomic is not especially good at representing historical data.)
- Infrastructure: Datomic is good for running on big server machines, typically in the Cloud - not on mobile devices or embedded systems.
- Proprietary: Datomic is not open-source, for some people that's a dealbreaker.
Conclusion
In addition to the Log of changes, Datomic provides a queriable snapshot (a ‘state’) of the entire database yielded by each change, all of this being directed by transactional writes. This is a significant technological feat, which explains why we can reap the benefits of Event Sourcing with much less effort and limitations than with conventional Event Sourcing implementations.
In more traditional CQRS parlance: Datomic gives you all in synchrony an expressive Command language (Datomic transaction requests), actionable Events (transactions as sets of added Datoms) and a powerful, relational default Aggregate (Datomic database values).
Hopefully this shows that Event Sourcing does not have to be as demanding as we've got accustomed to, so long as we're willing to rethink a bit our assumptions of how it should be implemented.
Finally, I should mention that this article offers a very narrow view of Datomic. There is more to Datomic than just being good at Event Sourcing! (The development workflow, the testing story, the composable writes, the flexible schema, the operational aspects...)
I've been overly politically correct in this entire article, and that must be pretty boring, so I'll leave you with this snarky provocative phrase:
Any sufficiently advanced conventional Event Sourcing system contains an ad-hoc, informally-specified, bug-ridden, slow implementation of half Datomic.
See also
- Event Sourcing: by Martin Fowler.
- Event Sourcing basics from the documentation of EventStore.
- Event Sourcing made simple: an explanation and experience report of Event Sourcing by Kickstarter engineering.
- Deconstructing the database by Rich Hickey, creator of Datomic.
- Is Kafka a database? a talk by Martin Kleppmann.
- As time goes by, episode 2: technical challenges of bi-temporal Event Sourcing
EDIT: this article has been discussed on Hacker News, r/programming and the DDD/CQRS mailing list.