What makes a good REPL?
- What does a good REPL give you?
- A smooth transition from manual to automated
- A REPL lets you improvise
- A REPL lets you write fewer tests, faster
- A REPL makes you write accessible code
- What makes a good REPL?
- What makes a programming language REPL-friendly?
- Conclusion
Dear Reader: although this post mentions Clojure as an example, it is not specifically about Clojure; please do not make it part of a language war. If you know other configurations which allow for a productive REPL experience, please describe them in the comments!
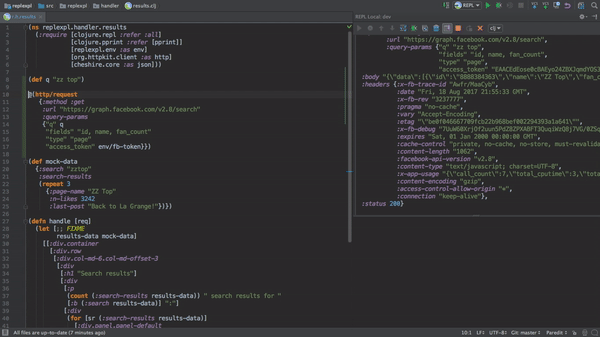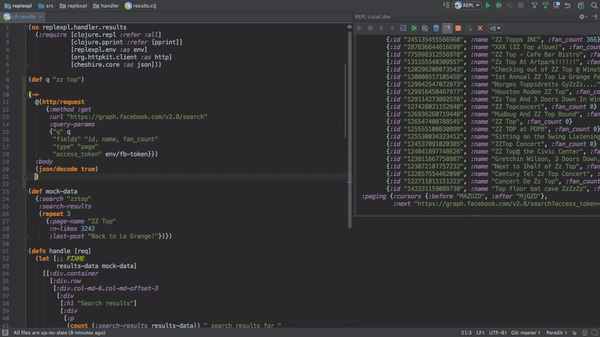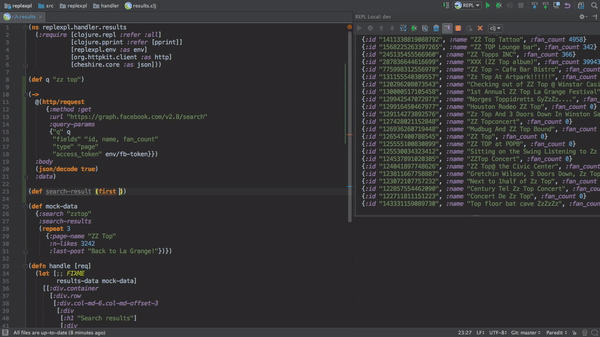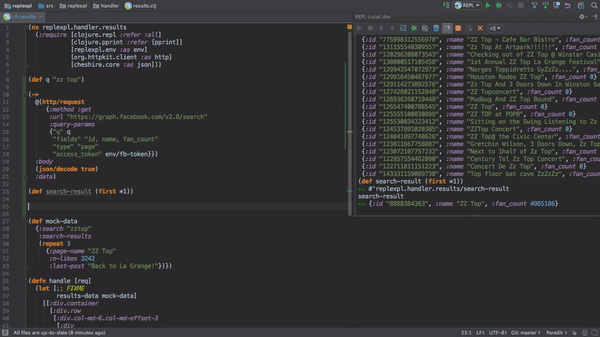
Most comparisons I see of Clojure to other programming languages are in terms of its programming language semantics: immutability, homoiconicity, data-orientation, dynamic typing, first-class functions, polymorphism 'à la carte'... All of these are interesting and valuable features, but what actually gets me to choose Clojure for projects is its interactive development story, enabled by the REPL (Read-Eval-Print Loop), which lets you evaluate Clojure expressions in an interactive shell (including expressions which let you modify the state or behaviour of a running program).
If you're not familiar with Clojure, you may be surprised that I describe the REPL as Clojure's most differentiating feature: after all, most industrial programming languages come with REPLs or 'shells' these days (including Python, Ruby, Javascript, PHP, Scala, Haskell, ...). However, I've never managed to reproduced the productive REPL workflow I had in Clojure with those languages; the truth is that not all REPLs are created equal.
In this post, I'll try to describe what a 'good' REPL gives you, then list some technical characteristics which make some REPLs qualify as 'good'. Finally, I'll try to reflect on what programming language features give REPLs the most leverage.
What does a good REPL give you?
The short answer is: by providing a tight feedback loop, and making your programs tangible, a REPL helps you deliver programs with significantly higher productivity and quality. If you're wondering why a tight feedback loop is important for creative activities such as programming, I recommend you watch this talk by Bret Victor.
If you have no idea what REPL-based development looks like, I suggest you watch a few minutes of the following video:
Now, here's the long answer: A good REPL gives you...
A smooth transition from manual to automated
The vast majority of the programs we write essentially automate tasks that humans can do themselves. Ideally, to automate a complex task, we should be able to break it down into smaller sub-tasks, then gradually automate each of the subtasks until reaching a fully-automated solution. If you were to build a sophisticated machine like a computer from scratch, you would want to make sure you understand how the individual components work before putting them together, right? Unfortunately, this is not what we get with the typical write/(compile)/run/watch-stdout workflow, in which we essentially put all the pieces together blindly and pray it works the first time we hit 'run'. The story is different with a REPL: you will have played with each piece of code in isolation before running the whole program, which makes you quite confident that each of the sub-tasks is well implemented.
This is also true in the other direction: when a fully-automated program breaks, in order to debug it, you will want to re-play some of the sub-tasks manually.
Finally, not all programs need be fully automated - sometimes the middle ground between manual and automated is exactly what you want. For instance, a REPL is a great environment to run ad hoc queries to your database, or perform ad hoc data analysis, while leveraging all of the automated code you have already written for your project - much better than working with database clients, especially when you need to query several data stores or reproduce advanced business logic to access the data.
How's life without a REPL? Here's a list of things that we do to cope with these issues when we don't have a REPL:
- Experiment with interactive tools such as cURL or database clients, then reproduce what we did in code. Problem: you can't connect these in any way with your existing codebase. These tools are good at experimenting manually, but then you have to code all the way to bridge the gap between making it work with these tools and having it work in your project.
- Run scripts which call our codebase to print to standard output our files. Problem: you need to know exactly what to output before writing the script; you can't hold on to program state and improvise from there, as we'll discuss in the next section.
- Use unit tests (possibly with auto-reloading), which have a number of limitations in this regard, as we'll see later in this post.
A REPL lets you improvise
Software programming is primarily and exploratory activity. If we had a precise idea of how our programs should work before writing them, we'd be using code, not writing it.
Therefore, we should be able to write our programs incrementally, one expression at a time, figuring out what to do next at each step, walking the machine through our current thinking. This is simply not what the compile/run-the-whole-thing/look-at-the-logs workflow gives you.
In particular, one situation where this ability is critical is fixing bugs in an emergency. When you have to reproduce the problem, isolate the cause, simulate the fix and finally apply it, a REPL is often the difference between minutes and hours.
Fun fact: maybe the most spectacular occurrence of this situation was the fixing of a bug of the Deep Space 1 probe in 1999, which fortunately happened to run a Common Lisp REPL while drifting off course several light-minutes away from Earth.
A REPL lets you write fewer tests, faster
Automated tests are very useful for expressing what your code is supposed to do, and giving you confidence that it works and keeps working correctly.
However, when I see some TDD codebases, it seems to me that a lot of unit tests are mostly here to make the code more tangible while developing, which is the same value proposition as using a REPL. However, using unit tests for this purpose comes with its lot of issues:
- Having too many unit tests makes your codebase harder to evolve. You ideally want to have as few tests as possible capture as many properties of your domain as possible.
- Tests can only ever answer close-ended questions: "does this work?", but not "how does this work?", "what does this look like?" etc.
- Tests typically won't run in real-world conditions: they'll use simple, artificial data and mocks of services such as databases or API clients. As a result, they don't typically help you understand a problem that only happens on real-life data, nor do they give you confidence that the real-life implementations of the services they emulate do work.
So it seems to me a lot of unit tests get written for lack of a better solution for interactivity, even though they don't really pull their weight as unit tests. When you have a REPL, you can make the choice to only write the tests that matter.
What's more, the REPL helps you write these tests. Once you have explored from the REPL, you can just copy and paste some of the REPL history to get both example data and expected output. You can even use the REPL to assist you in writing the fixture data for your tests by generating it programmatically (everyone who has written comprehensive fixture datasets by hand knows how tedious this can get). Finally, when writing the tests require implementing some non-trivial logic (as is the case when doing Property-Based Testing), the productivity benefits of the REPL for writing code applies to writing tests as well.
Again, do not take from this that a REPL is a replacements for tests. Please do write tests, and let the REPL help you write the right tests effectively.
A REPL makes you write accessible code
A REPL-based workflow encourages you to write programs which manipulate values that are easy to fabricate. If you need to set up a complex graph of objects before you can make a single method call, you won't be very inclined to use the REPL.
As a result, you'll tend to write accessible code - with few dependencies, little environmental coupling, high modularity, and tangible inputs and outputs. This is likely to make your code more clear, easy to test, and easy to debug.
To be clear, this is an additional constraint on your code (it requires some upfront thinking to make your code REPL-friendly, just likes it requires some upfront thinking to make your code easy to test) - but I believe it's a very beneficial constraint. When my car engine breaks, I'm glad I can just lift the hood and access all the parts - and making this possible has certainly put more work on the plate of car designers.
Another way a REPL makes code more accessible is that it makes it easier to learn, by providing a rich playground for beginners to experiment. This applies to both learning languages and onboarding existing projects.
What makes a good REPL?
As I said above, not all REPLs give you the same power. Having experimented with REPLs in various configurations of language and tooling, this is the list of the main things I believe a REPL should enable you to do to give you the most leverage:
- Defining new behaviour / modify existing behaviour. For instance, in a procedural language, this means defining new functions, and modify the implementation of existing functions.
- Saving state in-memory. If you can't hold on to the data you manipulate, you will waster a ton of effort re-obtaining it - it's like doing your paperwork without a desk.
- Outputting values which can easily be translated to code. This means that the textual representation the REPL outputs is suitable for being embedded in code.
- Giving you access to your whole project code. You should be able to call any piece of code written in your project of its dependencies. As an execution platform, the REPL should reproduce the conditions of running code in production as much as possible.
- Putting you in the shoes of your code. Given any piece of code in one of your project files, the REPL should let you put yourself in the same 'context' as that piece of code - e.g write some new code as if it was in the same line of the same source file, with the same lexical scope, runtime environment, etc. (in Clojure, this is provided by the
(in-ns ...)- 'in namespace' - function). - Interacting with a running program. For instance, if you're developing a web server, you want to be able to both run the webserver and interact with it from the REPL at the same time, e.g changing the implementation of a route and seing the change in your web browser, or sending a request from your web browser and intercepting it in your REPL. This implies some form of concurrency support, as the program state needs to be accessed by at least 2 independent logical processes (machine events and REPL interactions).
- Synchronizing REPL state with source code files. This means, for instance, 'loading' a source code file in the REPL, and then seeing all behaviour and state it defines effected in the REPL.
- Being editor-friendly. That is, exposing a communication interface which can be leveraged programmatically by an editor Desirable features include syntax highlighting, pretty-printing, code completion, sending code from editor buffers to the REPL, pasting editor output to editor buffers, and offering data visualization tools. (To be fair, this depends at least as much on the tooling around the REPL than on the REPL itself)
What makes a programming language REPL-friendly?
I said earlier that Clojure's semantics were less valuable to me than its REPL; however, these two issues are not completely separate. Some languages, because their semantics, are more or less compatible with REPL-based development. Here is my attempt at listing the main programming language features which make a proficient REPL workflow possible:
- Data literals. That is, the values manipulated in the programs have a textual representation which is both readable for humans and executable as code. The most famous form of data literals is the JavaScript object Notation (JSON). Ideally, the programming language should make it idiomatic to write programs in which most of the values can be represented by data literals.
- Immutability. When programming in a REPL, you're both holding on to evaluation results and viewing them in a serialized form (text in the output); what's more, since most of the work you're doing is experimental, you want to be able confine the effects of evaluating code (most of the time, to no other effect than showing the result and saving it in memory). This means you'll tend to program with values, not side-effects. As such, programming languages which make it practical to program with immutable data structures are more REPL-friendly.
- Top-level definitions. Working at the REPL consists of (re-)defining data and behaviour globally. Some languages provide limited support for this (especially some class-based languages); sometimes they ship with REPLs that 'patch' some additional features to the language for this sole purpose, but in practice this results in an impedance mismatch between the REPL and an existing codebase - you should really be able to seamlessly transfer code from one to the other. More generally, the language should have semantics for re-defining code while the program is running - interactivity should not be an afterthought in language design!
- Expressive power. You may think it's a bit silly to mention this one, but it's not a given. For the levels of sophistication we are aiming for, we need our languages to have clear and concise syntax which can express powerful abstractions that we know how to run efficiently, and there is no level of interactivity that can make up for those needs. This is why we don't write most of our programs as Bash scripts.
Conclusion
If you've ever played live music on stage without being able to hear your own instrument, then you have a good idea of how I feel when I program without a REPL - powerless and unconfident.
We like to discuss the merits of programming languages and libraries in terms of the abstractions they provide - yet we have to acknowledge that tooling plays an equally significant role. Most of us have experienced it with advanced editors, debuggers, and version control to name a few, but very few of us have had the chance to experience it with full-featured REPLs. Hopefully this blog post will contribute to righting that wrong :).
EDIT 2017-08-28: this article has been discussed on Hacker News, r/programming and r/Clojure.